文章目录
- 三元组含义
- 如何构建知识图谱
- 模型的整体结构
- 基于transformers框架的三元组抽取baseline
- how to use
- 预训练模型下载地址
- 训练数据下载地址
- 结构图
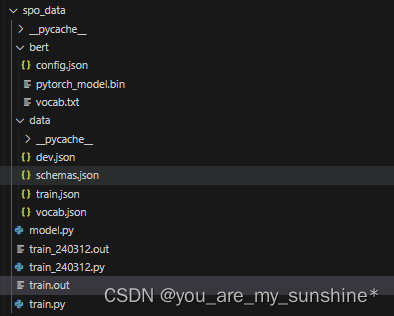
- 代码及数据
- bert
- config.json
- vocab.txt
- data
- dev.json
- schemas.json
- train.json
- vocab.json
- 与bert跟data同个目录
- model.py
- train.py
- 三元组实战小结
三元组含义
知识图谱的三元组,指的是 <subject, predicate/relation, object> 。同学们会发现很多人类的知识都可以用这样的三元组来表示。例如:<中国,首都,北京>,<美国,总统,特朗普> 等等。
所有图谱中的数据都是由三元组构成
工业场景通常把三元组存储在图数据库中如neo4j,图数据的优势在于能快捷查询数据。
学术界会采用RDF的格式存储数据,RDF的优点在于易于共享数据。
如何构建知识图谱
构建知识图谱通常有两种数据源
1、结构化数据,存储在关系型数据库中的数据,通过定义好图谱的schema,然后按照schema的格式,把关系型数据转化为图数据。
2、非结构化数据,通常又包括了纯文本形式和基于表格的形式,通常采用模板或者模型的方式,从文本中抽取出三元组再入库。
在实际的工业场景中,数据往往是最难处理的,这和比赛情况完全不同,比赛的数据较为干净、公整。但是在工业场景中,会出现难以构建schema、数据量极少、无标注数据等情况。
所以,对于不同的情况我们应该采用不同的处理方式,而不是一味的去采用模型处理。例如表格数据,其实采用规则的方式效果会很不错。
模型的整体结构
该模型只是一个baseline,还有很多的优化空间,大家可以根据自己的理解与想法,去迭代升级模型。
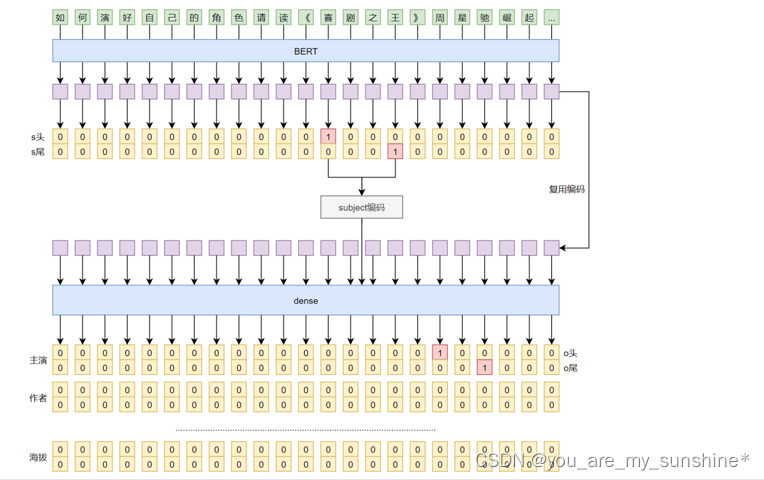
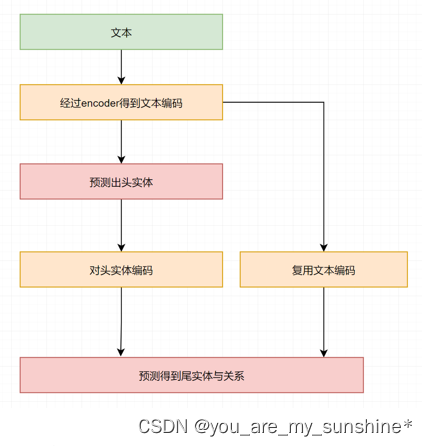
模型的整体结构如左图所示,输入是一段文本信息,经过encoder层进行编码,提取出头实体,再对头实体编码并复用文本编码,接下来用了个小trick,同时预测尾实体与关系,当然你也可以分开先预测尾实体,再预测关系。
对于实体的预测,我们可以使用BIO的方式,这里我们换一种思路,半指针半标注。
接下里我们看个具体的例子

句子案例:周星驰主演了喜剧之王,周星驰还演了其它的电影…
基于transformers框架的三元组抽取baseline
how to use
下载预训练模型,放到bert目录下,下载训练数据放到data目录下
安装transformers,pip install transformers
执行train.py文件
预训练模型下载地址
bert https://huggingface.co/bert-base-chinese/tree/main
roberta https://huggingface.co/hfl/chinese-roberta-wwm-ext/tree/main
训练数据下载地址
链接:https://pan.baidu.com/s/1rNfJ88OD40r26RR0Lg6Geg 提取码:a9ph
结构图
代码及数据
bert
config.json
{
"architectures": [
"BertForMaskedLM"
],
"attention_probs_dropout_prob": 0.1,
"directionality": "bidi",
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"initializer_range": 0.02,
"intermediate_size": 3072,
"layer_norm_eps": 1e-12,
"max_position_embeddings": 512,
"model_type": "bert",
"num_attention_heads": 12,
"num_hidden_layers": 12,
"output_past": true,
"pad_token_id": 0,
"pooler_fc_size": 768,
"pooler_num_attention_heads": 12,
"pooler_num_fc_layers": 3,
"pooler_size_per_head": 128,
"pooler_type": "first_token_transform",
"type_vocab_size": 2,
"vocab_size": 21128
}
vocab.txt
data
dev.json
[
{
"text": "查尔斯·阿兰基斯(Charles Aránguiz),1989年4月17日出生于智利圣地亚哥,智利职业足球运动员,司职中场,效力于德国足球甲级联赛勒沃库森足球俱乐部",
"spo_list": [
[
"查尔斯·阿兰基斯",
"出生地",
"圣地亚哥"
],
[
"查尔斯·阿兰基斯",
"出生日期",
"1989年4月17日"
]
]
},
......
]
schemas.json
[
{
"0": "所属专辑",
"1": "出品公司",
"2": "作曲",
"3": "总部地点",
"4": "目",
"5": "制片人",
"6": "导演",
"7": "成立日期",
"8": "出生日期",
"9": "嘉宾",
"10": "专业代码",
"11": "所在城市",
"12": "母亲",
"13": "妻子",
"14": "编剧",
"15": "身高",
"16": "出版社",
"17": "邮政编码",
"18": "主角",
"19": "主演",
"20": "父亲",
"21": "官方语言",
"22": "出生地",
"23": "改编自",
"24": "董事长",
"25": "国籍",
"26": "海拔",
"27": "祖籍",
"28": "朝代",
"29": "气候",
"30": "号",
"31": "作词",
"32": "面积",
"33": "连载网站",
"34": "上映时间",
"35": "创始人",
"36": "丈夫",
"37": "作者",
"38": "首都",
"39": "歌手",
"40": "修业年限",
"41": "简称",
"42": "毕业院校",
"43": "主持人",
"44": "字",
"45": "民族",
"46": "注册资本",
"47": "人口数量",
"48": "占地面积"
},
{
"所属专辑": 0,
"出品公司": 1,
"作曲": 2,
"总部地点": 3,
"目": 4,
"制片人": 5,
"导演": 6,
"成立日期": 7,
"出生日期": 8,
"嘉宾": 9,
"专业代码": 10,
"所在城市": 11,
"母亲": 12,
"妻子": 13,
"编剧": 14,
"身高": 15,
"出版社": 16,
"邮政编码": 17,
"主角": 18,
"主演": 19,
"父亲": 20,
"官方语言": 21,
"出生地": 22,
"改编自": 23,
"董事长": 24,
"国籍": 25,
"海拔": 26,
"祖籍": 27,
"朝代": 28,
"气候": 29,
"号": 30,
"作词": 31,
"面积": 32,
"连载网站": 33,
"上映时间": 34,
"创始人": 35,
"丈夫": 36,
"作者": 37,
"首都": 38,
"歌手": 39,
"修业年限": 40,
"简称": 41,
"毕业院校": 42,
"主持人": 43,
"字": 44,
"民族": 45,
"注册资本": 46,
"人口数量": 47,
"占地面积": 48
}
]
train.json
[
{
"text": "如何演好自己的角色,请读《演员自我修养》《喜剧之王》周星驰崛起于穷困潦倒之中的独门秘笈",
"spo_list": [
[
"喜剧之王",
"主演",
"周星驰"
]
]
},
......
]
vocab.json
[
{
"2": "如",
"3": "何",
......
"7028": "鸏",
"7029": "溞"
},
{
"如": 2,
"何": 3,
......
"鸏": 7028,
"溞": 7029
}
]
与bert跟data同个目录
model.py
from transformers import BertModel, BertPreTrainedModel
import torch.nn as nn
import torch
class SubjectModel(BertPreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.bert = BertModel(config)
self.dense = nn.Linear(config.hidden_size, 2)
def forward(self,
input_ids,
attention_mask=None):
output = self.bert(input_ids, attention_mask=attention_mask)
subject_out = self.dense(output[0])
subject_out = torch.sigmoid(subject_out)
return output[0], subject_out
class ObjectModel(nn.Module):
def __init__(self, subject_model):
super().__init__()
self.encoder = subject_model
self.dense_subject_position = nn.Linear(2, 768)
self.dense_object = nn.Linear(768, 49 * 2)
def forward(self,
input_ids,
subject_position,
attention_mask=None):
output, subject_out = self.encoder(input_ids, attention_mask)
subject_position = self.dense_subject_position(subject_position).unsqueeze(1)
object_out = output + subject_position
# [bs, 768] -> [bs, 98]
object_out = self.dense_object(object_out)
# [bs, 98] -> [bs, 49, 2]
object_out = torch.reshape(object_out, (object_out.shape[0], object_out.shape[1], 49, 2))
object_out = torch.sigmoid(object_out)
object_out = torch.pow(object_out, 4)
return subject_out, object_out
train.py
import json
from tqdm import tqdm
import os
import numpy as np
from transformers import BertTokenizer, AdamW, BertTokenizerFast
import torch
from model import ObjectModel, SubjectModel
GPU_NUM = 0
device = torch.device(f'cuda:{GPU_NUM}') if torch.cuda.is_available() else torch.device('cpu')
vocab = {}
with open('bert/vocab.txt', encoding='utf_8')as file:
for l in file.readlines():
vocab[len(vocab)] = l.strip()
def load_data(filename):
"""加载数据
单条格式:{'text': text, 'spo_list': [[s, p, o],[s, p, o]]}
"""
with open(filename, encoding='utf-8') as f:
json_list = json.load(f)
return json_list
# 加载数据集
train_data = load_data('data/train.json')
valid_data = load_data('data/dev.json')
tokenizer = BertTokenizerFast.from_pretrained('bert')
with open('data/schemas.json', encoding='utf-8') as f:
json_list = json.load(f)
id2predicate = json_list[0]
predicate2id = json_list[1]
def search(pattern, sequence):
"""从sequence中寻找子串pattern
如果找到,返回第一个下标;否则返回-1。
"""
n = len(pattern)
for i in range(len(sequence)):
if sequence[i:i + n] == pattern:
return i
return -1
def sequence_padding(inputs, length=None, padding=0, mode='post'):
"""Numpy函数,将序列padding到同一长度
"""
if length is None:
length = max([len(x) for x in inputs])
pad_width = [(0, 0) for _ in np.shape(inputs[0])]
outputs = []
for x in inputs:
x = x[:length]
if mode == 'post':
pad_width[0] = (0, length - len(x))
elif mode == 'pre':
pad_width[0] = (length - len(x), 0)
else:
raise ValueError('"mode" argument must be "post" or "pre".')
x = np.pad(x, pad_width, 'constant', constant_values=padding)
outputs.append(x)
return np.array(outputs)
def data_generator(data, batch_size=3):
batch_input_ids, batch_attention_mask = [], []
batch_subject_labels, batch_subject_ids, batch_object_labels = [], [], []
texts = []
for i, d in enumerate(data):
text = d['text']
texts.append(text)
encoding = tokenizer(text=text)
input_ids, attention_mask = encoding.input_ids, encoding.attention_mask
# 整理三元组 {s: [(o, p)]}
spoes = {}
for s, p, o in d['spo_list']:
# cls x x x sep
s_encoding = tokenizer(text=s).input_ids[1:-1]
o_encoding = tokenizer(text=o).input_ids[1:-1]
# 找对应的s与o的起始位置
s_idx = search(s_encoding, input_ids)
o_idx = search(o_encoding, input_ids)
p = predicate2id[p]
if s_idx != -1 and o_idx != -1:
s = (s_idx, s_idx + len(s_encoding) - 1)
o = (o_idx, o_idx + len(o_encoding) - 1, p)
if s not in spoes:
spoes[s] = []
spoes[s].append(o)
if spoes:
# subject标签
subject_labels = np.zeros((len(input_ids), 2))
for s in spoes:
# 注意要+1,因为有cls符号
subject_labels[s[0], 0] = 1
subject_labels[s[1], 1] = 1
# 一个s对应多个o时,随机选一个subject
start, end = np.array(list(spoes.keys())).T
start = np.random.choice(start)
# end = np.random.choice(end[end >= start])
end = end[end >= start][0]
subject_ids = (start, end)
# 对应的object标签
object_labels = np.zeros((len(input_ids), len(predicate2id), 2))
for o in spoes.get(subject_ids, []):
object_labels[o[0], o[2], 0] = 1
object_labels[o[1], o[2], 1] = 1
# 构建batch
batch_input_ids.append(input_ids)
batch_attention_mask.append(attention_mask)
batch_subject_labels.append(subject_labels)
batch_subject_ids.append(subject_ids)
batch_object_labels.append(object_labels)
if len(batch_subject_labels) == batch_size or i == len(data) - 1:
batch_input_ids = sequence_padding(batch_input_ids)
batch_attention_mask = sequence_padding(batch_attention_mask)
batch_subject_labels = sequence_padding(batch_subject_labels)
batch_subject_ids = np.array(batch_subject_ids)
batch_object_labels = sequence_padding(batch_object_labels)
yield [
torch.from_numpy(batch_input_ids).long(), torch.from_numpy(batch_attention_mask).long(),
torch.from_numpy(batch_subject_labels), torch.from_numpy(batch_subject_ids),
torch.from_numpy(batch_object_labels)
]
batch_input_ids, batch_attention_mask = [], []
batch_subject_labels, batch_subject_ids, batch_object_labels = [], [], []
if os.path.exists('graph_model.bin'):
print('load model')
model = torch.load('graph_model.bin').to(device)
subject_model = model.encoder
else:
subject_model = SubjectModel.from_pretrained('./bert')
subject_model.to(device)
model = ObjectModel(subject_model)
model.to(device)
train_loader = data_generator(train_data, batch_size=8)
optim = AdamW(model.parameters(), lr=5e-5)
loss_func = torch.nn.BCELoss()
model.train()
class SPO(tuple):
"""用来存三元组的类
表现跟tuple基本一致,只是重写了 __hash__ 和 __eq__ 方法,
使得在判断两个三元组是否等价时容错性更好。
"""
def __init__(self, spo):
self.spox = (
spo[0],
spo[1],
spo[2],
)
def __hash__(self):
return self.spox.__hash__()
def __eq__(self, spo):
return self.spox == spo.spox
def train_func():
train_loss = 0
pbar = tqdm(train_loader)
for step, batch in enumerate(pbar):
optim.zero_grad()
input_ids = batch[0].to(device)
attention_mask = batch[1].to(device)
subject_labels = batch[2].to(device)
subject_ids = batch[3].to(device)
object_labels = batch[4].to(device)
subject_out, object_out = model(input_ids, subject_ids.float(), attention_mask)
subject_out = subject_out * attention_mask.unsqueeze(-1)
object_out = object_out * attention_mask.unsqueeze(-1).unsqueeze(-1)
subject_loss = loss_func(subject_out, subject_labels.float())
object_loss = loss_func(object_out, object_labels.float())
# subject_loss = torch.mean(subject_loss, dim=2)
# subject_loss = torch.sum(subject_loss * attention_mask) / torch.sum(attention_mask)
loss = subject_loss + object_loss
train_loss += loss.item()
loss.backward()
optim.step()
pbar.update()
pbar.set_description(f'train loss:{loss.item()}')
if step % 1000 == 0 and step != 0:
torch.save(model, 'graph_model.bin')
with torch.no_grad():
# texts = ['如何演好自己的角色,请读《演员自我修养》《喜剧之王》周星驰崛起于穷困潦倒之中的独门秘笈',
# '茶树茶网蝽,Stephanitis chinensis Drake,属半翅目网蝽科冠网椿属的一种昆虫',
# '爱德华·尼科·埃尔南迪斯(1986-),是一位身高只有70公分哥伦比亚男子,体重10公斤,只比随身行李高一些,2010年获吉尼斯世界纪录正式认证,成为全球当今最矮的成年男人']
X, Y, Z = 1e-10, 1e-10, 1e-10
pbar = tqdm()
for data in valid_data[0:100]:
spo = []
# for text in texts:
text = data['text']
spo_ori = data['spo_list']
en = tokenizer(text=text, return_tensors='pt')
_, subject_preds = subject_model(en.input_ids.to(device), en.attention_mask.to(device))
# !!!
subject_preds = subject_preds.cpu().data.numpy()
start = np.where(subject_preds[0, :, 0] > 0.6)[0]
end = np.where(subject_preds[0, :, 1] > 0.5)[0]
subjects = []
for i in start:
j = end[end >= i]
if len(j) > 0:
j = j[0]
subjects.append((i, j))
# print(subjects)
if subjects:
for s in subjects:
index = en.input_ids.cpu().data.numpy().squeeze(0)[s[0]:s[1] + 1]
subject = ''.join([vocab[i] for i in index])
# print(subject)
_, object_preds = model(en.input_ids.to(device),
torch.from_numpy(np.array([s])).float().to(device),
en.attention_mask.to(device))
object_preds = object_preds.cpu().data.numpy()
for object_pred in object_preds:
start = np.where(object_pred[:, :, 0] > 0.2)
end = np.where(object_pred[:, :, 1] > 0.2)
for _start, predicate1 in zip(*start):
for _end, predicate2 in zip(*end):
if _start <= _end and predicate1 == predicate2:
index = en.input_ids.cpu().data.numpy().squeeze(0)[_start:_end + 1]
object = ''.join([vocab[i] for i in index])
predicate = id2predicate[str(predicate1)]
# print(object, '\t', predicate)
spo.append([subject, predicate, object])
print(spo)
# 预测结果
R = set([SPO(_spo) for _spo in spo])
# 真实结果
T = set([SPO(_spo) for _spo in spo_ori])
# R = set(spo_ori)
# T = set(spo)
# 交集
X += len(R & T)
Y += len(R)
Z += len(T)
f1, precision, recall = 2 * X / (Y + Z), X / Y, X / Z
pbar.update()
pbar.set_description(
'f1: %.5f, precision: %.5f, recall: %.5f' % (f1, precision, recall)
)
pbar.close()
print('f1:', f1, 'precision:', precision, 'recall:', recall)
for epoch in range(100):
print('************start train************')
# 训练
train_func()
# min_loss = float('inf')
# dev_loss = dev_func()
# if min_loss > dev_loss:
# min_loss = dev_loss
# torch.save(model,'model.p')
三元组实战小结
模型的整体结构:输入是一段文本信息,经过encoder层进行编码,提取出头实体,再对头实体编码并复用文本编码,接下来用了个小trick,同时预测尾实体与关系。对于实体的预测思路是,半指针半标注。
学习的参考资料:
七月在线NLP高级班
代码参考:
https://github.com/terrifyzhao/spo_extract